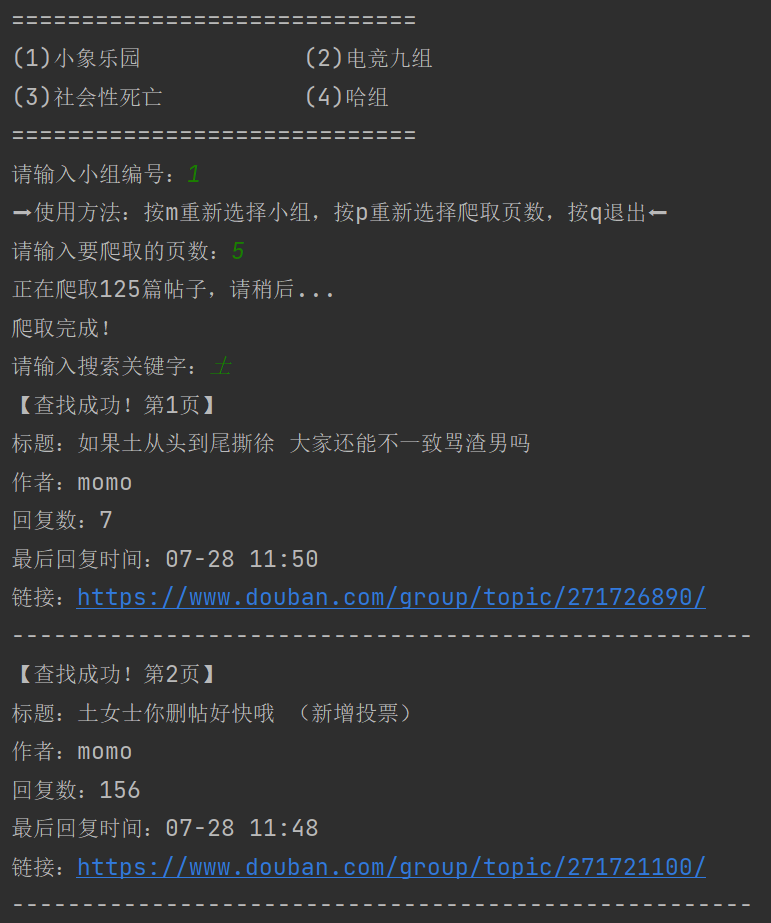
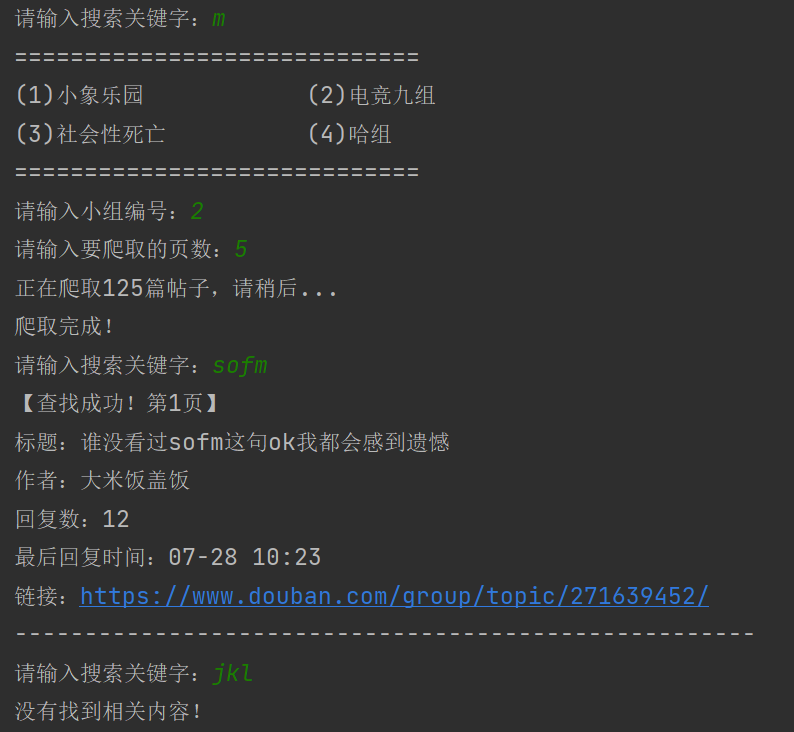
deflist_posts(response, page, titles, urls, dates, authors, replies): tree = etree.HTML(response) titles_arr = tree.xpath('//table[@class="olt"]/tr//td/a/@title') for t inrange(len(titles_arr)): titles[page].append(titles_arr[t]) urls_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="title"]//a/@href') for u inrange(len(urls_arr)): urls[page].append(urls_arr[u]) dates_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="time"]/text()') for d inrange(len(dates_arr)): dates[page].append(dates_arr[d]) authors_arr = tree.xpath('//table[@class="olt"]/tr//td[@nowrap="nowrap"]/a/text()') for a inrange(len(authors_arr)): authors[page].append(authors_arr[a]) replies_arr = tree.xpath('//table[@class="olt"]/tr//td[@class="r-count "]/text()') for r inrange(len(replies_arr)): replies[page].append(replies_arr[r]) return titles, urls, dates, authors, replies
defget_page(all_page, group_url): titles = [[] for i inrange(all_page)] urls = [[] for i inrange(all_page)] dates = [[] for i inrange(all_page)] authors = [[] for i inrange(all_page)] replies = [[] for i inrange(all_page)] for i inrange(all_page): start = i * 25 response = get_code(start, group_url) titles, urls, dates, authors, replies = list_posts(response, i, titles, urls, dates, authors, replies) return titles, urls, dates, authors, replies






 微信
微信 支付宝
支付宝

